盡管以太坊的許多理念在早先的密碼學貨幣(如比特幣)上已經運用并測試了5年之久,但從某些協議功能的處理方法上來說,以太坊與常見方式仍有許多不同。而且,以太坊可用于開發全新的經濟工具,因為它具有其他系統不具備的許多功能。本文會詳細描述以太坊所有的潛在優點,以及在構建以太坊協議過程中某些有爭議的地方。另外,也會指出我們的方案及替代方案的潛在風險。
原則
以太坊協議的設計遵循以下幾點原則:
三明治復雜模型(亦可譯為 “復雜度分層模型” ):我們認為以太坊的底層協議應盡可能的簡單,接口設計應易于理解(不論是面向開發者的高級編程語言接口,還是面向用戶的使用接口)。那些不可避免的復雜部分應放入中間層。中間層不作文核心共識的一部分,且對最終用戶不可見,它包含:高級語言編譯器、參數序列化和反序列化腳本、存儲數據結構模型、leveldb 存儲接口以及聯網協議等。當然,區分的界線不是絕對明確的,有時候需要酌情調整。
自由:不應限制用戶使用以太坊協議,也不應試圖優先支持或不支持某些以太坊合約或交易。這一點與 “網絡中立” 概念背后的指導原則相似。比特幣交易協議就 沒有 遵循這一原則:比特幣交易協議并不鼓勵區塊鏈的 “非常規用途(off-labal purpose)” (如,數據存儲,元協議)(校對注:off-labal 的原意為將藥物用在其經過批準的適應癥之外的癥狀上,例如使用止咳藥來治療頭痛。此處意譯為 “非常規用途” );而且,有時候還有人用 準-協議層 的變更(例如將 OP_RETURN 字段的長度限制在 40 字節)來攻擊以 “未經授權” 的方式使用區塊鏈的應用(校對注:此處是在諷刺比特幣的社區有審查比特幣區塊鏈用法的傾向)。因此,在以太坊,我們堅定支持僅使用交易手續費來達成大體激勵相容的辦法 —— 用戶消耗整個網絡越多資源,需要付出的代價就越高,也即使其自己承擔成本(即庇古稅)。
泛化:以太坊協議的特性和操作碼應最大限度地體現低層次的概念(就像基本粒子一樣),以便它們可以隨意組合,包括組合出今天看來沒什麼用、但未來可能有用的東西。而且,通過剝離那些不需要的功能,低層次的概念可以更加高效。遵循這一原則的例子是,我們選擇 LOG 操作碼作為向 dapp 提供信息的方式,而不是像之前那樣記錄下所有交易和消息。在早先,“消息(message)” 的概念完完全全是多種概念的集合,它包含 “函數調用(function call)” 和 “外在觀察者感興趣的事件信息(event)” ,而兩者是完全可以分離開來的。
沒有特點就是最大的特點:為了遵循泛化原則,我們拒絕將那些高級用例內嵌為協議的一部分,哪怕是經常使用的用例,也絕不這麼做。如果人們真的想實現這些用例,可以在合約內創建子協議(如,基于以太坊的子貨幣,比特幣/萊特幣/狗幣的側鏈等)。比如,在以太坊中就缺少類似比特幣中的 “時間鎖” 功能。但是,通過以下協議可以模擬出這個功能:用戶發送簽名數據包到特定的合約中處理,如果數據包在特定合約中有效,則執行相應的函數。
不厭惡風險:如果風險的增加帶來了可觀的好處,我們愿意承擔更高的風險(例如,通用的狀態轉換,出塊時間減低 50 倍,共識效率,等等)。
這些原則指導著以太坊的開發,但它們并不是絕對的;某些情況下,為了減少開發時間或者不希望一次作出過多改變,也會使我們推遲作出某些修改,把它留到將來的版本中去修改。
區塊鏈層協議
本節對以太坊中區塊鏈層協議的改變進行了描述,包括區塊和交易是如何工作的、數據如何序列化及存儲、賬戶背后的機制。
賬戶 ,而非 UTXO 1
比特幣及其許多變種,都將用戶的余額信息存儲在 UTXO 結構中,系統的整個狀態由一系列的 “未花費的輸出” 組成(可以將這些 “未花費的輸出” 想象成錢幣)(校對注:更好的一個比喻可能是 “支票”。)。每個 UTXO 都有擁有者和自身的價值屬性。一筆交易在消費若干個 UTXO 同時也會生成若干個新的 UTXO;而交易受到下列有效性要求的約束:
1.每個被引用的輸入必須有效,且未被使用過;2.交易的簽名必須與每筆輸入的所有者簽名匹配;3.輸入的總值必須等于或大于輸出的總值。
因此,比特幣系統中,用戶的 “余額” 是該用戶的私鑰能夠有效簽名的所有 UTXO 的總和。下圖展示了比特幣系統中交易輸入輸出過程:
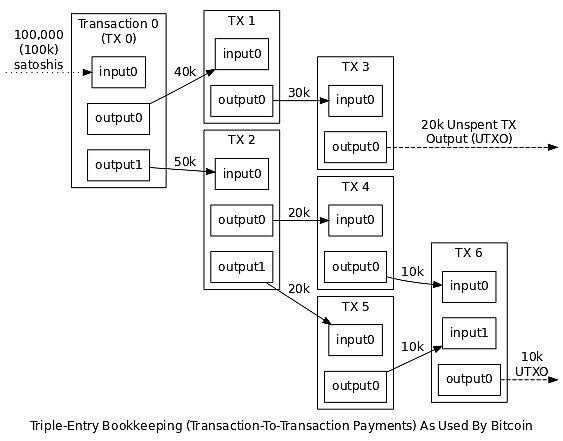

比特幣所用的三式記賬法
但是,以太坊拋棄了 UTXO 的方案,轉而使用更簡單的方法:采用狀態(state)的概念存儲一系列賬戶,每個賬戶都有自己的余額,以及以太坊特有的數據(代碼和內部存儲器)。如果交易發起方的賬戶余額足夠支付交易費用,則交易有效,那麼發起方賬戶會扣除相應金額,而接收賬戶則計入該金額。某些情況下,接收賬戶內有需要執行的代碼,則交易會觸發該代碼的執行,那麼賬戶的內部存儲器可能會發生變化,甚至可能會創建額外的消息發送給其他賬戶,從而導致新的交易發生。
盡管以太坊沒有采用 UTXO 的概念,但 UTXO 也不乏有一些優點:
較高程度的隱私保護:如果用戶每次交易都使用一個新的地址,那麼賬戶之間的相互關聯就很困難。這樣做適用于對安全性要求高的貨幣系統,但不是對任何 dapp 都合適。因為 dapp 通常需要跟蹤用戶復雜的綁定狀態,而 dapp 的狀態并不能像貨幣系統中的狀態那樣簡單地劃分。
潛在的可擴展性:理論上來說,UTXO 與某些類型的可擴展性方案(scalability paradigm)更契合,因為只需持幣者擁有能夠證明自己貨幣所有權的默克爾證明即可,即使所有的人(包括 TA 本人)都遺忘了這一數據,真正受損也這個人,其他人不受影響。在以太坊賬戶系統中,如果所有人都丟失了某個賬戶對應的默克爾樹部分,那麼該賬戶將無法處理任何能夠影響它的消息,包括發送給它的消息,它也無法處理。不過,并非只有 UTXO 能夠可擴展,也存在不依賴 UTXO 就能擴展的方式(此處沒有擴展開來講,譯者注)。
賬戶的好處有以下幾點:
節省大量空間:如果一個賬戶有 5 個 UTXO,則從 UTXO 模式轉成賬戶模式,所需空間會從 300 字節降到 30 字節。具體計算如下:300 = (20+32+8)* 5 (20 是地址字節數,32 是 TX 的 id 字節數,8 是面額占用的字節數); 30 = 20 + 8 + 2 (20 是地址字節數,8 是賬戶余額值字節數,2 是 nonce 2 字節數);但實際節約并沒有這麼大,因為賬戶需要被存儲在帕特里夏樹中。另外以太坊中交易也比比特幣中的更小(以太坊中 100 字節,比特幣中 200-250 字節),因為每次交易只需要生成一次引用,一次簽名,以及一個輸出。
可互換性更強:UTXO 結構并沒有區塊鏈層的概念,所以不管是在技術還是法律上,通過建立一個紅名單/黑名單,并依據的這些 “有效輸出” 的來源區分它們并不是很實際。
簡單:以太坊編碼更簡單、更易于理解,尤其是在涉及到復雜腳本時。盡管任何去中心化應用都可以用 UTXO 方式來(勉強)實現,但這種方式實質上是賦予腳本限制給定的 UTXO 所能輸出的 UTXO 的種類及其使用條件(比如需要包含默克爾樹證明來幫助腳本所對應的應用更改狀態根)的能力。因此,UTXO 實現方式比以太坊使用賬戶的方式要復雜的多。
輕客戶端:輕客戶端可以隨時通過沿指定方向掃描狀態樹來訪問與賬戶相關的所有數據。在 UTXO 范式中,每筆交易需要用到的引用都不同,這對于長時間運行并使用了上文提到的 UTXO 根狀態傳播機制的 dapp 應用來說,無疑是繁重的。
我們認為,賬戶的好處大大超過了其他方式,尤其是對于我們想要支持的、可包含任意狀態和代碼的 dapp 應用而言。另外,本著 “沒有特點就是最大的特點” 的指導原則,我們認為如果用戶真的關心私密性,則可以通過合約中的簽名數據包協議來建立一個加密 “混幣器(mixer and coinjoin)” 混淆支付路徑。
賬戶方式的一個弱點是:為了阻止重放攻擊(replay attack,指讓同一筆交易重復執行),每筆交易必須有一個 “nonce”(流水號)。因此,每個賬戶都要有一個實時更新的 nonce 值,每一筆新交易都在賬戶 nonce 值上遞增 1 作為自己的 nonce(并在交易處理之后按此值更新賬戶的 nonce 值)(校對注:在賬戶模式下,如果交易不附帶這種消耗性的標識符,交易就可被重復處理,這樣接收賬戶可以一遍又一遍地收賬且不用付出任何代價,而發賬的賬戶會被吸干;以太坊賬戶的 nonce 隨所發起的交易得到處理而遞增,就解決了這個問題)。這就意味著,即使不再使用的賬戶,也不能從賬戶狀態中移除。解決這個問題的一個簡單方法是讓交易包含一個區塊號,使它們在一段時間后就無法再被重放,并且每隔一段時間段重置 nonce。
若要在狀態中刪除某個賬戶(比如長期不使用的賬戶),就必須先 “ping” 出它們來,而完整掃描區塊鏈協議的開銷是非常大的。在1.0上我們沒有實現這個機制,1.1及以上版本可能會使用這個機制。
校對注:這就是以太坊日后面臨的 “狀態爆炸” 問題的技術原因:所有狀態數據必須完整保存,無法合理地刪除賬戶。作為一種區塊鏈協議,以太坊的節點不僅要對事務(交易)的順序達成共識,還要對全局狀態達成共識(表現形式就是區塊頭里需要包括狀態根。因此,若要刪除狀態,也需要全網的共識,否則會陷入分裂。
校對注:這種以 nonce 來標記賬戶交易順序的做法,也使得用戶的交易必須順序執行,如果一筆交易無法得到處理,使用后續 nonce 的交易也無法得到處理。關于 “加速” 已發出的交易的上鏈進度,見這篇文章。
默克爾帕特里夏樹(MPT)
默克爾帕特里夏樹(Merkle Patricia tree/trie),由 Alan Reiner 提出設想,并在瑞波協議中得到實現,是以太坊的主要數據結構,用于存儲所有賬戶狀態,以及每個區塊中的交易和收據數據。MPT 是默克爾樹和帕特里夏樹的結合,結合這兩種樹創建的結構具有以下屬性:
任一組 鍵-值對 所對應的根哈希值都是唯一的,想要謊稱某個 鍵值對 存在于某棵樹上是一定會被識破的(除非攻擊者擁有約 2^128 的算力)。
增、刪、改 一個鍵值對的時間復雜度是對數級別。
MPT為我們提供了一個高效、易更新、且代表整個狀態樹的 “指紋” 。關于MPT更詳細描述:https://github.com/ethereum/wiki/wiki/Patricia-Tree。
MPT的具體設計決策如下:
有兩類節點:KV 節點和離散節點。KV節點的存在提高了效率,因為如果在特定區域樹是稀疏的,KV節點可作為一個 “捷徑” 來壓縮樹的高度(閱讀 MPT 的詳述可了解更多細節)。
離散節點是十六進制,不是二進制:這樣讓查找更有效率,我們現在認識到這種選擇并不理想,因為十六進制樹的查找效率在二進制中可以通過批次存儲節點來模擬。但是,MPT 樹結構的實現是非常容易出錯的,最終至少會造成狀態根不匹配,所以我們決定擱置變更,等到 1.1 版本再說。
空值(empty value)與非成員(non-membership)之間沒有區別:這樣做是為了簡化邏輯,以太坊中未啟用的賬戶的值(余額)默認為 0,空字符串也用 0 表示。然而,需要強調的是,這樣做犧牲了一些通用性,因而也不是最優的。
終節點(terminating)和非終節點的區別:技術上,標識一個節點 “是否是終節點” 是沒必要的,因為以太坊中所有的樹都被用于存儲固定長度(即鍵的長度)的數據,但為了增加通用性,我們還是會添加這個標識,以期望以太坊的 MPT 的實現方式能夠被其他密碼學貨幣原樣采納。
在 “安全樹”(狀態樹和賬戶存儲樹)中采用 SHA3(k) 作為鍵:使用 SHA3(k),想要通過生成許多的賬戶(賬戶最多可讓狀態樹高達 64 層!)并重復調用 SLOAD 和 SSTORE 操作碼來 DoS 攻擊的難度會大大提高。注意,這也讓枚舉樹變得更困難;如果要使你的客戶端具備枚舉的功能,最簡單的方法就是維護一個映射 sha3(k) -> k 的數據庫。
校對注:這里的意思是,如果使用 k 作為默克爾樹存儲數據的鍵,其分布可能很稀疏,而攻擊者可以容易地規劃出需要很深的樹路徑來存儲的賬戶,并對這些賬戶重復調用狀態訪問操作,以此造成網絡中的節點超負荷運行,但是,哈希函數的結果是隨機分布的,以 sha3(k) 作為鍵可以使鍵的分布較為均勻,樹高也會較矮)。
這種特性也是有得有失,這一方面意味著 DoS 攻擊會變得更困難,另一方面,也使得一個區塊中的交易的狀態樹訪問路徑,很少有重合的,因此每次搜索都是復雜度最差的情形。
此外,這也使得 MPT 不宜實現 “無狀態性”(區塊自身攜帶驗證所需的數據、驗證者無需具有全局狀態),因為狀態訪問的路徑不重合,證據的空間效率也是最差情形。當然,也可以說,默克爾樹證據的空間效率本身也不夠高
RLP
RLP(recursive length prefix):遞歸長度前綴。
RLP 編碼是以太坊中主要的序列化格式,它的使用無處不在:區塊、交易、賬戶狀態以及網絡協議消息。詳見 RLP 正式描述: https://github.com/ethereum/wiki/wiki/RLP
RLP 旨在成為高度簡化的序列化格式,它唯一的目的是存儲嵌套的字節數組 3。不同于 protobuf、BSON 等現有的解決方案,RLP并不定義任何指定的數據類型,如 Boolean(布爾值)、float(浮點數)、double 或者 integer(整數)。它僅僅是以嵌套數組的形式存儲結構體,由協議來確定數組的含義。RLP 也沒有顯式支持 map 集合,半官方的建議是采用 [[k1, v1], [k2, v2], ...] 的嵌套數組來表示鍵值對集合,k1,k2 … 按照字符串的標準排序。
與 RLP 具有相同功能的方案是 protobuf 或 BSON,它們是一直被使用的算法。然而,以太坊中,我們更偏向于使用 RLP,因為:(1)它易于實現;(2)絕對保證字節的一致性。
許多語言的鍵值對集合沒有明確的排序,并且浮點格式有很多特殊情況,這可能造成相同數據卻產生不同編碼和不同哈希值。通過內部開發協議,我們能確保它是帶著這些目標設計的(這是一般原則,也適用于代碼的其他部分,如虛擬機)。BitTorrent 使用的編碼方式 bencode 也許可以替代 RLP。不過它采用的是十進制的編碼方式,與采用二進制的 RLP 相比,稍微遜色了點。
壓縮算法
網絡協議和數據庫都采用了一個自定義的壓縮算法來存儲數據。該算法可描述為:對 0 使用行程編碼 4 并同時保留其他值(除了一些特殊情況如 sha3(' ') ),舉例如下:
>>> compress('horse')'horse'>>> compress('donkey dragon 1231231243')'donkey dragon 1231231243'>>> compress('\xf8\xaf\xf8\xab\xa0\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xbe\xb2\xdc\xc7\x03\xc0\xe5\x00\xb6S\xca\x82';{\xfa\xd8\x04]\x85\xa4p")‘\xfe\x01'
壓縮算法存在之前,以太坊協議的許多地方都有一些特殊情況,例如,sha3 經常被重定義使得 sha3(' ')=' ',這樣不需要在賬戶中存儲代碼,可以節省 64 字節。然而,最近所有這些使得以太坊數據結構變得臃腫的特殊情況都被刪除了,取而代之的是將數據保存函數添加到區塊鏈協議之外的層,也就是將其放入網絡協議以及將其插入用戶數據庫實現。這樣增加了模塊化能力,簡化了共識層,使得對壓縮算法的持續更新部署起來相對簡單(例如:可通過網絡協議的版本號來區別、部署)。
樹(trie)的使用
提醒:理解這部分的知識需要讀者了解布隆過濾器 5 的原理。簡介可見:http://en.wikipedia.org/wiki/Bloom_filter
以太坊區塊鏈中每個區塊頭都包含指向三個樹的指針:狀態樹、交易樹、收據樹。
狀態樹代表處理完該區塊后的整個狀態;
交易樹代表區塊中所有交易,這些交易由 index 索引作為key;(例如,k0:第一個執行的交易,k1:第二個執行的交易)
收據樹代表每筆交易相應的收據。
交易的收據是一個 RLP 編碼的數據結構:
[ medstate, gas_used, logbloom, logs ]其中:
medstate:交易處理后,狀態樹的根;
gas_used:交易處理后,gas 的使用量;
logs:是許多 [address, [topic1, topic2...], data] 元素的列表。這些元素由交易執行期間調用的操作碼 LOG0 … LOG4 生成(包含主調用和子調用);address 是生成日志的合約的地址;topics 是最多 4 個 32 字節的值;data 是任意大小的字節數組;
logbloom:交易中所有 logs 的 address 和 topics 組成的布隆過濾器。
區塊頭中也存在一個布隆過濾器,它是區塊中交易的所有布隆過濾器的或運算(OR)結果。這樣的構造使得以太坊協議對輕客戶端友好得無以復加。
注釋:
UTXO:unspent transaction outputs,字面理解是:未花費的交易輸出,也即未被任何交易引用為輸入的交易輸出。它是比特幣協議中用于存儲價值(所有權)信息的數據結構。—— 校對注
Nonce,Number used once 或 Number once 的縮寫,在密碼學中 Nonce 是一個只被使用一次的任意或非重復的隨機數值,在加密技術中的初始向量和加密哈希函數都發揮著重要作用,在各類驗證協議的通信應用中確保驗證信息不被重復使用以對抗重放攻擊(Replay Attack)。—— 譯者注
嵌套數組:創建一個數組,并使用其他數組填充該數組。如數組 pets:
var cats : String[] = ["Cat","Beansprout", "Pumpkin", "Max"];
var dogs : String[] = ["Dog","Oly","Sib"];
var pets : String = [cats, dogs];
—— 譯者注
行程編碼(run-length-encoding):一種統計編碼。主要技術是檢測重復的比特或字符序列,并用它們的出現次數取而代之。(百度百科)—— 譯者注
布隆過濾器:由 Howard Bloom 在 1970 年提出的二進制向量數據結構,它具有很好的空間和時間效率,被用來檢測一個元素是不是集合中的一個成員。
發文者:鏈站長,轉載請註明出處:https://www.jmb-bio.com/4167.html
 微信扫一扫
微信扫一扫